El deep learning, o aprendizaje profundo, se trata de un subcampo dentro del machine learning que consiste en el entrenamiento de redes neuronales artificiales para que aprendan a partir de enormes volúmenes de información. Dichas redes se diseñan inspirándose en la estructura y función del cerebro humano y tienen la capacidad de reconocer patrones y conexiones en conjuntos de datos sumamente complicados. El deep learning ostenta el potencial de transformar numerosos ámbitos, abarcando desde la atención sanitaria hasta las finanzas y el entretenimiento.
- Explicación
- Historia Del Deep Learning
- Ejemplo Básico Con Python
- Ventajas Del Deep Learning
- Casos de Uso
- Avances Recientes
- Consideraciones Éticas
- El Futuro De Este Subcampo
- Conclusión
Explicación
El deep learning consiste en entrenar redes neuronales artificiales para que aprendan a partir de enormes volúmenes de información. Estas redes se componen de capas de nodos interconectados encargados de procesar y transmitir datos.
A lo largo del entrenamiento, la red neuronal recibe un extenso conjunto de datos y aprende a reconocer patrones y conexiones en la información ajustando la intensidad de las relaciones entre las neuronas. Este proceso se denomina retropropagación.
Una vez entrenada la red neuronal, esta se emplea para realizar predicciones o clasificaciones sobre datos nuevos. Por ejemplo, un modelo de deep learning entrenado con imágenes de gatos y perros podría utilizarse para determinar si una imagen nueva contiene algunos de estos dos animales.
Frameworks Populares
Los frameworks, traducido en marcos de trabajo, de deep learning son bibliotecas de software que permiten a los desarrolladores construir y entrenar modelos de manera eficiente. En forodatos recomendamos los siguientes:
- TensorFlow: creado por Google, es uno de los más utilizados y ofrece una amplia variedad de herramientas y características para construir y entrenar modelos de deep learning.
- Keras: una API de alto nivel que trabaja sobre TensorFlow. Está diseñada para ser fácil de usar y aprender, lo que la convierte en una opción popular para los principiantes.
- Caffe: creado por Berkeley AI Research, se caracteriza por su rápido tiempo de entrenamiento y se utiliza a menudo en aplicaciones que requieren procesamiento en tiempo real.
- PyTorch: desarrollado por Facebook, es reconocido por su facilidad de uso y flexibilidad. Es especialmente popular entre los investigadores y se utiliza a menudo para diseñar nuevos modelos.
- MXNet: un framework de deep learning de código abierto patrocinado por Apache. Destaca por su eficiencia y escalabilidad, permitiendo entrenamiento distribuido en múltiples GPUs y máquinas. Soporta varios lenguajes de programación como Python, R y Scala.
- Theano: desarrollado por el Instituto de Algoritmos de Aprendizaje de Montreal (MILA), está diseñado para ser eficiente y rápido, lo que lo convierte en una opción popular para investigadores y desarrolladores que necesitan trabajar con grandes conjuntos de datos.
La elección de un framework para deep learning depende de factores como la complejidad del modelo, el volumen del conjunto de datos y el nivel de experiencia del desarrollador. Cada entorno cuenta con sus propias ventajas y desventajas.
Historia Del Deep Learning
Aunque las raíces del deep learning se remontan a los primeros días de la inteligencia artificial, el progreso en el campo de las redes neuronales artificiales fue lento hasta el advenimiento de la retropropagación, una técnica para entrenar redes neuronales. La retropropagación se describió por primera vez en la década de 1970, pero no fue hasta las décadas de 1980 y 1990 cuando comenzó a usarse para entrenar redes neuronales profundas.
En los últimos años, ha experimentado un resurgimiento del interés gracias en parte a la disponibilidad de grandes conjuntos de datos y mayor poder computacional. Actualmente, el deep learning es un campo en rápido crecimiento, con nuevos avances y aplicaciones que surgen todo el tiempo.
Ejemplo Básico Con Python
El conjunto de datos CIFAR-10, que contiene 60,000 imágenes en color de 32×32 píxeles divididas en 10 clases, se carga utilizando el código proporcionado. Las imágenes se normalizan dividiéndolas por 255 para que sus valores estén en el rango [0, 1], lo que ayuda a mejorar la convergencia del entrenamiento. Luego, se visualizan algunas imágenes del conjunto de datos junto con sus etiquetas.
A continuación, se crea una red neuronal convolucional (CNN) utilizando la API Keras de TensorFlow. La CNN tiene tres capas convolucionales intercaladas con capas de pooling para extraer características relevantes de las imágenes. Las capas convolucionales utilizan filtros de 3×3 y activación ReLU, mientras que las capas de pooling utilizan MaxPooling2D con un tamaño de ventana de 2×2. Después de estas capas, se aplana el tensor resultante y se añaden dos capas densas (fully connected) con activación ReLU y Softmax.
El modelo se compila especificando el optimizador Adam, la función de pérdida sparse categorical crossentropy y la métrica de precisión. Luego, se entrena la CNN durante 20 épocas «epochs» utilizando los datos de entrenamiento y validación. Una vez entrenado, se evalúa el rendimiento del modelo en el conjunto de datos de prueba y se muestra la precisión obtenida.
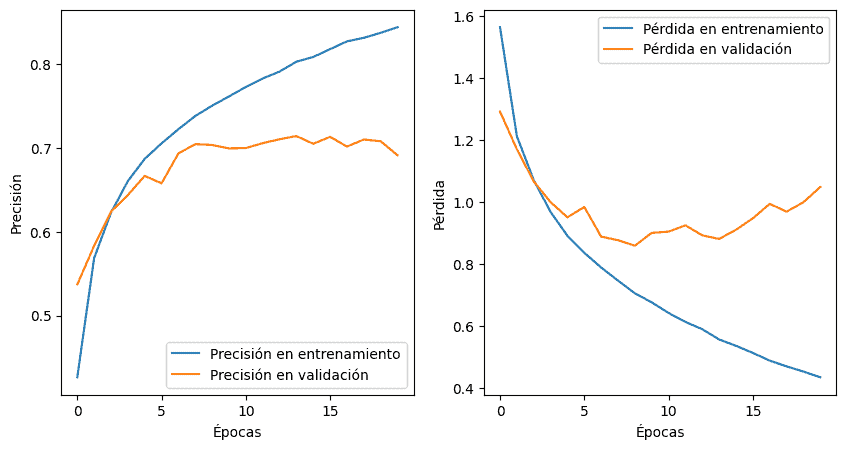
Antes de concluir, se define una función para visualizar la evolución de la precisión y la pérdida durante el entrenamiento en gráficos de línea, y se utilizan estos gráficos para mostrar cómo la precisión y la pérdida cambian a medida que el modelo se entrena a lo largo de las épocas.
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
import matplotlib.pyplot as plt
# Cargamos y normalizamos el conjunto de datos CIFAR-10
(imagenes_entrenamiento, etiquetas_entrenamiento), (imagenes_prueba, etiquetas_prueba) = tf.keras.datasets.cifar10.load_data()
imagenes_entrenamiento, imagenes_prueba = imagenes_entrenamiento / 255.0, imagenes_prueba / 255.0
# Creamos una función para visualizar algunas imágenes del conjunto de datos
def mostrar_imagenes(imagenes, etiquetas, nombres_clases):
fig, ejes = plt.subplots(3, 3)
for i, eje in enumerate(ejes.flat):
eje.imshow(imagenes[i])
eje.set_title(nombres_clases[etiquetas[i][0]])
eje.axis("off")
plt.show()
# Definimos los nombres de las clases
nombres_clases = ['avión', 'automóvil', 'pájaro', 'gato', 'ciervo', 'perro', 'rana', 'caballo', 'barco', 'camión']
# Visualizamos algunas imágenes del conjunto de datos
mostrar_imagenes(imagenes_entrenamiento, etiquetas_entrenamiento, nombres_clases)
# Creamos la arquitectura de la CNN
modelo = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# Compilamos el modelo
modelo.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Entrenamos la CNN
historial = modelo.fit(imagenes_entrenamiento, etiquetas_entrenamiento, epochs=20, validation_data=(imagenes_prueba, etiquetas_prueba))
# Evaluamos el rendimiento del modelo en el conjunto de prueba
perdida_prueba, precision_prueba = modelo.evaluate(imagenes_prueba, etiquetas_prueba, verbose=2)
print('Precisión en el conjunto de prueba:', precision_prueba)
# Visualizamos la evolución de la precisión y la pérdida durante el entrenamiento
def graficar_historial(historial):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(historial.history['accuracy'], label='Precisión en entrenamiento')
plt.plot(historial.history['val_accuracy'], label='Precisión en validación')
plt.xlabel('Épocas')
plt.ylabel('Precisión')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(historial.history['loss'], label='Pérdida en entrenamiento')
plt.plot(historial.history['val_loss'], label='Pérdida en validación')
plt.xlabel('Épocas')
plt.ylabel('Pérdida')
plt.legend()
plt.show()
graficar_historial(historial)
----------------------------------------------------------------------------------
# Obtendremos un resultado similar a lo siguiente:
# Imágenes pertenecientes al conjunto de datos
 # Épocas de entrenamiento de la CNN
Epoch 1/20
1563/1563 [==============================] - 95s 60ms/step - loss: 1.5652 - accuracy: 0.4265 - val_loss: 1.2929 - val_accuracy: 0.5372
Epoch 2/20
1563/1563 [==============================] - 83s 53ms/step - loss: 1.2134 - accuracy: 0.5687 - val_loss: 1.1714 - val_accuracy: 0.5833
Epoch 3/20
1563/1563 [==============================] - 86s 55ms/step - loss: 1.0718 - accuracy: 0.6228 - val_loss: 1.0676 - val_accuracy: 0.6240
Epoch 4/20
1563/1563 [==============================] - 82s 53ms/step - loss: 0.9690 - accuracy: 0.6605 - val_loss: 1.0007 - val_accuracy: 0.6438
Epoch 5/20
1563/1563 [==============================] - 82s 52ms/step - loss: 0.8922 - accuracy: 0.6870 - val_loss: 0.9518 - val_accuracy: 0.6667
Epoch 6/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.8373 - accuracy: 0.7055 - val_loss: 0.9850 - val_accuracy: 0.6578
Epoch 7/20
1563/1563 [==============================] - 85s 54ms/step - loss: 0.7898 - accuracy: 0.7224 - val_loss: 0.8894 - val_accuracy: 0.6935
Epoch 8/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.7475 - accuracy: 0.7381 - val_loss: 0.8779 - val_accuracy: 0.7046
Epoch 9/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.7066 - accuracy: 0.7504 - val_loss: 0.8602 - val_accuracy: 0.7036
Epoch 10/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.6773 - accuracy: 0.7615 - val_loss: 0.9015 - val_accuracy: 0.6995
Epoch 11/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.6430 - accuracy: 0.7728 - val_loss: 0.9056 - val_accuracy: 0.6999
Epoch 12/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.6140 - accuracy: 0.7829 - val_loss: 0.9259 - val_accuracy: 0.7057
Epoch 13/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5906 - accuracy: 0.7911 - val_loss: 0.8935 - val_accuracy: 0.7104
Epoch 14/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5575 - accuracy: 0.8029 - val_loss: 0.8819 - val_accuracy: 0.7142
Epoch 15/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5371 - accuracy: 0.8086 - val_loss: 0.9117 - val_accuracy: 0.7050
Epoch 16/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.5141 - accuracy: 0.8179 - val_loss: 0.9484 - val_accuracy: 0.7133
Epoch 17/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.4893 - accuracy: 0.8272 - val_loss: 0.9953 - val_accuracy: 0.7017
Epoch 18/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.4708 - accuracy: 0.8314 - val_loss: 0.9700 - val_accuracy: 0.7101
Epoch 19/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.4539 - accuracy: 0.8374 - val_loss: 1.0003 - val_accuracy: 0.7080
Epoch 20/20
1563/1563 [==============================] - 82s 52ms/step - loss: 0.4357 - accuracy: 0.8440 - val_loss: 1.0496 - val_accuracy: 0.6913
313/313 - 4s - loss: 1.0496 - accuracy: 0.6913 - 4s/epoch - 12ms/step
Precisión en el conjunto de prueba: 0.6912999749183655
# Gráficas de precisión y pérdida durante el entrenamiento
# Épocas de entrenamiento de la CNN
Epoch 1/20
1563/1563 [==============================] - 95s 60ms/step - loss: 1.5652 - accuracy: 0.4265 - val_loss: 1.2929 - val_accuracy: 0.5372
Epoch 2/20
1563/1563 [==============================] - 83s 53ms/step - loss: 1.2134 - accuracy: 0.5687 - val_loss: 1.1714 - val_accuracy: 0.5833
Epoch 3/20
1563/1563 [==============================] - 86s 55ms/step - loss: 1.0718 - accuracy: 0.6228 - val_loss: 1.0676 - val_accuracy: 0.6240
Epoch 4/20
1563/1563 [==============================] - 82s 53ms/step - loss: 0.9690 - accuracy: 0.6605 - val_loss: 1.0007 - val_accuracy: 0.6438
Epoch 5/20
1563/1563 [==============================] - 82s 52ms/step - loss: 0.8922 - accuracy: 0.6870 - val_loss: 0.9518 - val_accuracy: 0.6667
Epoch 6/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.8373 - accuracy: 0.7055 - val_loss: 0.9850 - val_accuracy: 0.6578
Epoch 7/20
1563/1563 [==============================] - 85s 54ms/step - loss: 0.7898 - accuracy: 0.7224 - val_loss: 0.8894 - val_accuracy: 0.6935
Epoch 8/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.7475 - accuracy: 0.7381 - val_loss: 0.8779 - val_accuracy: 0.7046
Epoch 9/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.7066 - accuracy: 0.7504 - val_loss: 0.8602 - val_accuracy: 0.7036
Epoch 10/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.6773 - accuracy: 0.7615 - val_loss: 0.9015 - val_accuracy: 0.6995
Epoch 11/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.6430 - accuracy: 0.7728 - val_loss: 0.9056 - val_accuracy: 0.6999
Epoch 12/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.6140 - accuracy: 0.7829 - val_loss: 0.9259 - val_accuracy: 0.7057
Epoch 13/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5906 - accuracy: 0.7911 - val_loss: 0.8935 - val_accuracy: 0.7104
Epoch 14/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5575 - accuracy: 0.8029 - val_loss: 0.8819 - val_accuracy: 0.7142
Epoch 15/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.5371 - accuracy: 0.8086 - val_loss: 0.9117 - val_accuracy: 0.7050
Epoch 16/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.5141 - accuracy: 0.8179 - val_loss: 0.9484 - val_accuracy: 0.7133
Epoch 17/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.4893 - accuracy: 0.8272 - val_loss: 0.9953 - val_accuracy: 0.7017
Epoch 18/20
1563/1563 [==============================] - 80s 51ms/step - loss: 0.4708 - accuracy: 0.8314 - val_loss: 0.9700 - val_accuracy: 0.7101
Epoch 19/20
1563/1563 [==============================] - 81s 52ms/step - loss: 0.4539 - accuracy: 0.8374 - val_loss: 1.0003 - val_accuracy: 0.7080
Epoch 20/20
1563/1563 [==============================] - 82s 52ms/step - loss: 0.4357 - accuracy: 0.8440 - val_loss: 1.0496 - val_accuracy: 0.6913
313/313 - 4s - loss: 1.0496 - accuracy: 0.6913 - 4s/epoch - 12ms/step
Precisión en el conjunto de prueba: 0.6912999749183655
# Gráficas de precisión y pérdida durante el entrenamiento
Es importante destacar que el ejemplo presentado en este código es altamente relevante y útil en la industria y en la investigación. Las habilidades aprendidas en la creación, entrenamiento y evaluación de una CNN en un conjunto de datos como CIFAR-10 pueden ser empleadas en una variedad de tareas en visión por computadora, incluyendo el reconocimiento de objetos, la inspección visual automatizada en procesos de fabricación e incluso en la clasificación de imágenes médicas.
Ejemplos así también ser utilizan para la clasificación de imágenes satelitales y en problemas más específicos y complejos de la industria. Mediante la pertinente adaptación y aplicación de esta tecnología se pueden desarrollar soluciones eficientes en la clasificación y análisis de imágenes en una variedad de campos.
Ventajas Del Deep Learning
Presenta varias ventajas importantes, entre ellas, su habilidad para procesar y analizar grandes volúmenes de datos de manera eficiente y precisa. Esto lo hace especialmente útil en campos como la atención médica, las finanzas y el entretenimiento, donde se manejan grandes conjuntos de datos con frecuencia.
Otra ventaja del deep learning es su capacidad para detectar patrones y relaciones complejas en los datos que suelen pasar desapercibidos para los seres humanos. Esta capacidad lo convierte en algo de valor para tareas como el reconocimiento de imágenes y voz.
Los modelos pueden mejorarse y perfeccionarse continuamente a través del entrenamiento, lo que les permite adaptarse a nuevas situaciones y entornos.
Limitaciones
A pesar de sus muchas ventajas, es importante tener en cuenta las limitaciones del deep learning como:
- Requisitos computacionales: los modelos requieren de una cantidad significativa de potencia y recursos computacionales para su entrenamiento, lo que suele resultar costoso y llevar mucho tiempo.
- Falta de transparencia: la complejidad de los modelos de deep learning puede dificultar su interpretación y explicación, lo que dificulta la identificación de errores o sesgos en el modelo.
- Sobreajuste: los modelos tienden a sobreajustarse a los datos de entrenamiento, lo que significa que igual funcionan bien con esos datos, pero mal con nuevos datos no vistos anteriormente.
Casos de Uso
El deep learning ha demostrado su utilidad en diversos campos, incluyendo:

- Procesamiento del lenguaje natural: ha facilitado el desarrollo de sistemas de procesamiento del lenguaje natural capaces de entender y generar lenguaje humano con gran precisión. Las aplicaciones del procesamiento del lenguaje natural incluyen asistentes virtuales, chatbots y herramientas de traducción de idiomas.
- Visión por computadora: ha permitido el desarrollo de sistemas de visión por computadora que pueden identificar objetos, caras y otros elementos visuales en imágenes y videos con una gran precisión. Las aplicaciones de la visión por computadora incluyen automóviles autónomos, sistemas de seguridad e imágenes médicas.
- Cuidado de la salud: también ha permitido el desarrollo de sistemas para el análisis de imágenes médicas, el diagnóstico de enfermedades y el descubrimiento de fármacos. Estas aplicaciones tienen el potencial de mejorar los resultados de los pacientes y reducir los costes de atención médica.
- Reconocimiento de voz: ha sido esencial en el desarrollo de sistemas de reconocimiento de voz que pueden transcribir el habla con gran precisión y responder a comandos de voz. Las aplicaciones del reconocimiento de voz incluyen asistentes de voz, software de dictado y bots de servicio al cliente.
- Finanzas: se ha utilizado en finanzas para desarrollar sistemas para la detección de fraudes, la predicción del precio de las acciones y la evaluación de riesgos. Con el fin de ayudar a las instituciones financieras a tomar decisiones más informadas y mejorar sus resultados financieros.
Avances Recientes
La evolución del deep learning ha llevado a muchos avances recientes en la tecnología. Algunos de estos desarrollos notables son:
- Transferencia de aprendizaje: esta técnica permite que los modelos de deep learning aprendan de modelos previamente entrenados, lo que reduce la cantidad de datos necesarios para entrenar nuevos modelos y mejora la precisión del modelo.
- Mecanismos de atención: los mecanismos de atención permiten que los modelos se centren en partes específicas de los datos de entrada, mejorando la precisión de tareas como el procesamiento del lenguaje natural.
- Redes adversarias generativas (GAN): las GAN son un tipo de modelo que utiliza dos redes entrenadas simultáneamente para generar datos sintéticos realistas. Se utiliza en aplicaciones como la síntesis de imágenes y videos.
- Aprendizaje por refuerzo: este enfoque se utiliza para entrenar modelos de toma de decisiones basados en recompensas y penalizaciones-castigos Se ha utilizado en áreas como la robótica y los vehículos autónomos.
Estos avances han abierto nuevas posibilidades para su aplicación en áreas como la atención médica, las finanzas y el transporte.
Consideraciones Éticas
Al igual que con cualquier tecnología relacionada con datos y sistemas inteligentes, el deep learning presenta importantes consideraciones éticas que deben tenerse en cuenta al trabajar con los modelos pertinentes. Algunas de las cuestiones éticas clave que rodean a los modelos de deep learning son:
- Sesgo: pueden estar sesgados si los datos de entrenamiento están sesgados. Es importante asegurarse de que los datos se recopilen de manera ética y representen una amplia gama de perspectivas para evitar la discriminación (étnica, religiosa…) en los resultados.
- Privacidad: a menudo requieren grandes cantidades de datos personales. Es importante garantizar que estos datos se recopilen y utilicen de manera ética y que se proteja la privacidad de los individuos.
- Responsabilidad: a medida que los modelos de deep learning se vuelven más complejos y difíciles de interpretar, puede ser un desafío hacerlos responsables de sus acciones. Garantizar que los modelos de deep learning sean transparentes y entrenados de manera responsable es esencial para generar confianza en sus aplicaciones.
- Interacción humana: pueden automatizar muchas tareas-oficios realizados por humanos. Sin embargo, es importante considerar el impacto potencial en el empleo y el desplazamiento laboral, así como las implicaciones sociales y psicológicas de interactuar con máquinas inteligentes.
Para abordar estas consideraciones éticas, se requiere un enfoque multidisciplinario que involucre a expertos en campos como la informática, la filosofía, el derecho y la sociología. Es importante asegurarse de que el deep learning se desarrolle y utilice de manera ética, transparente y equitativa para garantizar un impacto positivo en la sociedad y la humanidad en general.
El Futuro De Este Subcampo
No cabe duda de que el deep learning seguirá desempeñando un papel importante en la evolución de la tecnología en los próximos años. Se espera que el campo avance aún más en áreas como:
- Sistemas autónomos: tendrá un papel fundamental en el desarrollo de sistemas autónomos como vehículos autónomos y drones, lo que llevará a una mayor eficiencia y seguridad en el transporte y la logística.
- Robótica: se espera que se utilice para desarrollar robots inteligentes que puedan aprender de su entorno y realizar tareas complejas, lo que tendrá aplicaciones en la industria manufacturera, la salud y la exploración espacial.
- Personalización: se utilizará para desarrollar sistemas personalizados que se adapten a los usuarios individuales en áreas como la atención médica, la educación y el comercio electrónico, lo que mejorará la experiencia del usuario y aumentará la eficiencia.
- Comprensión del lenguaje natural: seguirá avanzando en la comprensión del lenguaje natural, lo que permitirá el desarrollo de sistemas que puedan entender y generar lenguaje natural de manera similar a los humanos. Esto tendrá aplicaciones en áreas como la traducción de idiomas, la atención al cliente y la creación de contenido.
De nuevo, todo ello sin olvidar la importancia de seguir trabajando en el desarrollo y ética del deep learning para garantizar su impacto positivo en la sociedad.
Conclusión
El deep learning es un campo en constante evolución con el potencial de transformar muchas industrias. Su habilidad para procesar y analizar grandes cantidades de datos de manera rápida y precisa lo hace una herramienta de gran utilidad para identificar patrones y relaciones en conjuntos de datos complejos. Sin embargo, también tiene limitaciones importantes, como los requisitos computacionales y la falta de transparencia. Pese a ello, el futuro se ve prometedor, con nuevos avances y aplicaciones emergiendo constantemente.
