
La ingeniería de características (en inglés, feature engineering) es fundamental en la construcción de modelos de machine learning. Abarcando la creación, transformación y selección de características a partir de datos sin procesar, con el objetivo de mejorar el rendimiento del modelo. En este artículo, explicaremos con detalle en qué consiste este término, incluyendo sus técnicas e importancia, así como otra información de utilidad.
- Explicación
- Supuestos Prácticos
- Técnicas Avanzadas de Ingeniería de Características
- Recomendaciones
- Conclusión
Explicación
La ingeniería de características es el proceso de crear atributos que mejoren el rendimiento de un algoritmo de machine learning, utilizando el conocimiento específico de los datos.
Este proceso es importante porque la calidad de las características determina el límite superior del rendimiento del modelo. Si las características de entrada no son buenas, el modelo no podrá alcanzar un correcto desempeño.
En Qué Consiste El Proceso
El proceso de ingeniería de características consta de 3 fases:
1. Creación de Características
La creación de características implica generar nuevas características a partir de las originales. Esto puede variar desde operaciones matemáticas simples, combinaciones de características, hasta transformaciones más complejas:
- Transformaciones Matemáticas: se aplican funciones matemáticas como logaritmos y raíces cuadradas-exponenciales a las características existentes.
- Interacciones entre Características: crean nuevas características combinando dos o más características existentes, como la multiplicación y división de variables.
- Características Polinomiales: se generan características elevando las variables originales a diferentes potencias y/o combinándolas en términos polinomiales.
2. Selección de Características
En esta etapa se identifican y eligen las características más relevantes para el problema. Destacamos los siguientes métodos:
- Métodos Basados en Filtros: usan estadísticas para evaluar la importancia de cada característica de manera independiente del modelo, como la correlación o la prueba de chi-cuadrado.
- Métodos Basados en Wrappers: evalúan la importancia de las características utilizando un modelo de machine learning, como la eliminación recursiva de características.
- Métodos Basados en Embedded: integran la selección de características dentro del proceso de entrenamiento del modelo, como los coeficientes de regresión en modelos lineales con regularización.
3. Transformación de Características
En esta última fase se modifican las características existentes para mejorar su utilidad en el modelo, se lleva a cabo mediante:
- Normalización & Escalado: ajustando el rango de las características para que tengan una escala similar, lo que suele mejorar el rendimiento de algunos algoritmos.
- Codificación de Variables Categóricas: convirtiendo variables categóricas en un formato que los algoritmos puedan procesar, como la codificación one-hot o la codificación ordinal.
- Imputación de Valores Faltantes: lidiando con datos faltantes rellenándolos con valores calculados, como la media, la mediana, y también utilizando técnicas más avanzadas como imputación por k-NN.
Ejemplo Con Código Python
Para entender mejor lo anterior, veremos las fases aplicadas a un dataset de bienes raíces para predecir el precio de venta de las viviendas. Incluyendo diversas características relacionadas como superficie, número de habitaciones y año de construcción. En el siguiente código se detalla cómo se pueden manipular y preparar estos datos para la modelización, implementando técnicas de preprocesamiento estándar y métodos avanzados de selección de características (dentro de un pipeline estructurado).
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.metrics import mean_squared_error
import seaborn as sns
import matplotlib.pyplot as plt
def load_data(file_path):
"""
Cargamos un dataset desde un archivo CSV.
Args:
file_path (str): la ruta al archivo CSV.
Returns:
pd.DataFrame: el df cargado desde el CSV.
"""
return pd.read_csv(file_path)
# 1. Creación de Características
def create_features(df):
"""
Añade características derivadas al dfpara enriquecer el modelo.
Args:
df (pd.DataFrame): dataframe original.
Returns:
pd.DataFrame: dataframe enriquecido con nuevas características.
"""
current_year = datetime.now().year
df['EdadVivienda'] = current_year - df['AñoConstruccion']
df['Renovada'] = df['AñoRenovacion'].notnull().astype(int)
return df
def setup_preprocessing(num_features, cat_features):
"""
Configura el proceso de transformación de los datos para las características numéricas y categóricas.
Args:
num_features (list of str): nombres de las características numéricas.
cat_features (list of str): nombres de las características categóricas.
Returns:
ColumnTransformer: el transformador de columnas configurado.
"""
num_transformer = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
cat_transformer = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
return ColumnTransformer([
('num', num_transformer, num_features),
('cat', cat_transformer, cat_features)
])
def run_modeling_pipeline(df, num_features, cat_features):
"""
Ejecuta el pipeline de modelado completo, desde el preprocesamiento hasta la evaluación.
Args:
df (pd.DataFrame): dataframe con los datos "crudos".
num_features (list of str): lista de características numéricas.
cat_features (list of str): lista de características categóricas.
Returns:
float: el error cuadrático medio (MSE) del modelo.
"""
preprocessor = setup_preprocessing(num_features, cat_features)
pipeline = Pipeline([
('preprocessor', preprocessor),
('selector', SelectKBest(score_func=f_regression, k=10)),
('regressor', RandomForestRegressor(n_estimators=100, random_state=42))
])
X = df[num_features + cat_features]
y = df['PrecioVenta']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
plt.figure(figsize=(10, 6))
sns.scatterplot(x=y_test, y=y_pred)
plt.xlabel('Valores Reales')
plt.ylabel('Valores Predichos')
plt.title('Comparación de Valores Reales y Predichos')
plt.show()
return mse
def main():
file_path = 'https://forodatos.com/multimedia/datos/viviendas_features.csv'
df = load_data(file_path)
df = create_features(df)
num_features = ['Superficie', 'NumHabitaciones', 'NumBaños', 'EdadVivienda']
cat_features = ['TipoVivienda', 'CalidadConstruccion', 'EstadoConservacion', 'Barrio', 'TipoCalle']
mse = run_modeling_pipeline(df, num_features, cat_features)
print(f'Error cuadrático medio (MSE): {mse}')
if __name__ == "__main__":
main()
------------------------------------------------------------------------------------------------------------------------------------------------------------
Error cuadrático medio (MSE): 14627198705.435904
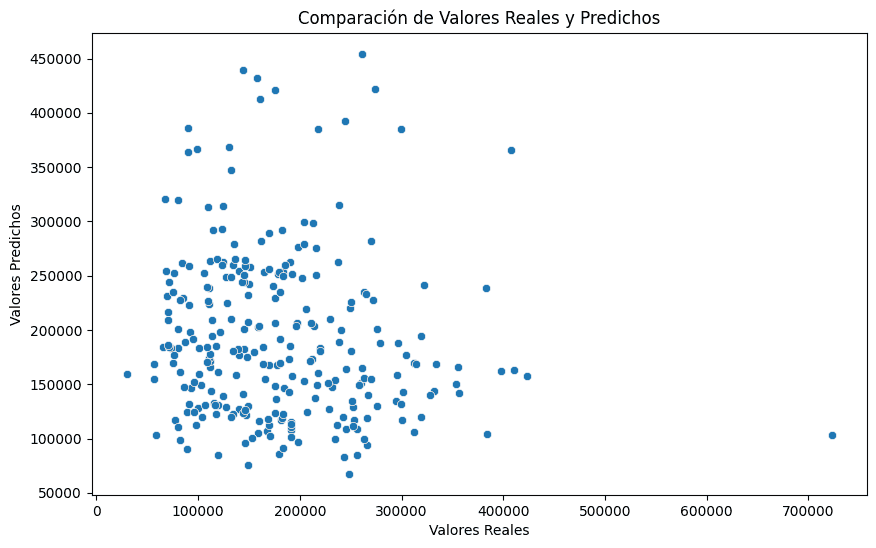
El error cuadrático medio es demasiado elevado, y el gráfico de dispersión se muestra lejano a una alineación en la identidad y=x. Esto quiere decir que el modelo es muy poco preciso en sus predicciones.
Se ha empleado un dataset sintético, y el objetivo de introducir este código en el artículo es poder ayudar a comprender mejor las fases del proceso de ingeniería de características.
Se comienza con la carga de datos, seguida por una meticulosa creación de nuevas características, como la edad de la vivienda y si ha sido renovada-reformada o no.
Posteriormente, se transforman la características para manejar los valores faltantes y normalizar las escalas de los datos, asegurando que el modelo pueda interpretar correctamente las variables numéricas y categóricas. Una vez hecho esto, se entrena un modelo de regresión random forest, y se evalúa su precisión mediante el error cuadrático medio, complementado con visualizaciones para comparar predicciones y valores reales.
La Importancia Que Tiene
- Mejora el Rendimiento del Modelo: una buena estructuración y elección de características hace que aumente la precisión y robustez del modelo, permitiéndole aprender patrones más complejos y realizar predicciones más precisas.
- Reduce la Dimensionalidad: la selección de características reduce el número de características de entrada, lo que no solo mejora la eficiencia computacional sino que también ayuda a mitigar problemas de overfitting.
Supuestos Prácticos
En este apartado veremos 2 supuestos prácticos de ingeniería de características que podrían darse en un contexto profesional, explicando lo que conllevaría las etapas de creación, transformación y selección:
Ejemplo 1: Clasificación de Correo Electrónico
Para un problema de clasificación de correos electrónicos en spam o no spam, podríamos tener características originales como el número de palabras, la presencia de ciertas palabras clave y la longitud del correo electrónico:
- Creación de Características: crear una característica binaria que indique si el correo contiene una dirección URL, lo cual podría ser un fuerte indicativo de spam.
- Transformación de Características: aplicar una transformación TF-IDF (Term Frequency-Inverse Document Frequency) a las palabras del correo para captar la importancia de cada palabra en el contexto del conjunto de datos.
- Selección de Características: usar la técnica de selección basada en el valor chi-cuadrado para identificar las palabras que más contribuyen a la clasificación de spam.
La implementación de estas técnicas mejoraría la precisión del modelo de clasificación, permitiendo una mejor identificación y gestión de correos electrónicos no deseados.
Ejemplo 2: Predicción de Abandono de Clientes
Una empresa de telecomunicaciones quiere predecir qué clientes abandonarán el servicio. En este supuesto se procedería de la siguiente manera:

- Creación de Características: generar características como el tiempo total en llamadas, el número de llamadas al servicio al cliente, y la variación mensual en el gasto.
- Transformación de Características: normalizar las características de gasto y tiempo en llamadas.
- Selección de Características: usar algoritmos como random forest para identificar las características más relevantes.
El resultado sería una mejora significativa en la precisión del modelo de predicción, permitiendo a la empresa tomar medidas proactivas para intentar retener a los clientes en riesgo.
Técnicas Avanzadas de Ingeniería de Características
La ingeniería de características no se limita simplemente a la creación y selección básica de atributos; también abarca métodos avanzados que aprovechan algoritmos de machine learning para mejorar la representación de los datos. Estas técnicas facilitan el descubrir interacciones complejas y patrones ocultos capaces de mejorar notablemente el rendimiento de los modelos predictivos.
I) Basadas en Machine Learning
Además de las técnicas tradicionales, hay métodos avanzados que utilizan algoritmos de machine learning para crear y seleccionar características:
- Machine Learning Automatizado: herramientas como Google AutoML y H2O.ai incluyen capacidades para la ingeniería automática de características, lo que acelera el proceso y ayuda a descubrir interacciones complejas entre las variables.
- Aprendizaje Embedido: en modelos de deep learning, los embeddings se utilizan para representar características categóricas en un espacio continuo, capturando relaciones complejas y mejorando el rendimiento del modelo. Por ejemplo, los embeddings de palabras en el procesamiento del lenguaje natural capturan el contexto semántico de las palabras.
II) Basadas en Series Temporales
Para datos temporales, existen las siguientes técnicas específicas:
- Descomposición de Series Temporales: dividir una serie temporal en componentes de tendencia, estacionalidad y ruido para crear nuevas características que puedan capturar mejor los patrones temporales.
- Lag Features: crear características basadas en valores pasados (lags) de la serie temporal para capturar dependencias temporales.
- Rolling Statistics: utilizar ventanas móviles para calcular estadísticas como medias, desviaciones estándar y sumas acumuladas, lo que puede resaltar patrones locales en los datos.
III) Basadas en Grafos
Para datos que tienen una estructura de red o gráfica, como redes sociales o sistemas de recomendación, se pueden utilizar técnicas de ingeniería de características basadas en grafos:
- Node Embeddings: generar representaciones vectoriales de nodos en un grafo utilizando técnicas como Node2Vec o Graph Convolutional Networks.
- Medidas de Centralidad: calcular medidas de centralidad (como grado, cercanía, y betweenness) para capturar la importancia relativa de los nodos en la red.
Recomendaciones
- Comprender los Datos: es recomendable comprender con detalle los datos y el contexto en el que se está trabajando, lo que incluye conocer la distribución de características, la presencia de valores faltantes y la relación entre diferentes características.
- Experimentar & Validar: es importante experimentar con diferentes técnicas y validar su impacto en el rendimiento del modelo. Utilizando técnicas como la validación cruzada para ayudar a asegurarse de que las mejoras observadas no se deban a la casualidad.
- Automatizar: automatizar el proceso de ingeniería de características ayuda a mejorar la eficiencia y la reproducibilidad del proyecto. Librerías Python como Featuretools y el módulo pipeline de Scikit-learn son de utilidad para este propósito.
- Considerar la Interpretabilidad: particularmente en campos como la medicina y las finanzas, se deben considerar la interpretabilidad de las características creadas – es decir, que sean intuitivas y comprensibles para que los resultados del modelo puedan ser explicados adecuadamente.
Problemas Asociados
En la ingeniería de características, la escalabilidad se transforma en un handicap cuando se procesan grandes volúmenes de datos, requiriendo de técnicas de big data y computación distribuida para mejorar la eficiencia. El sesgo y la variabilidad pueden aparecer si la creación y selección de características no se realiza de manera inteligente, por lo que es necesario siempre garantizar que las características sean justas y representativas del problema a tratar.
Otro problema-limitación a tener en cuenta es el overfitting, que consiste en que el modelo aprende patrones específicos del conjunto de entrenamiento pero no rinde bien con un conjunto diferente. Esto se evita utilizando técnicas como la validación cruzada y la regularización, dotando al modelo de la capacidad de realizar predicciones precisas con datos diversos.
Conclusión
La ingeniería de características es ideal para el machine learning, ya que mejora la calidad y el rendimiento de los modelos a través de la transformación y selección de características adecuadas. Con el constante avance de la tecnología y la ya conocida importancia de los datos, la ingeniería de características mantendrá su importancia en el desarrollo de soluciones de inteligencia artificial y análisis big data.
